


Moonlight — news, told well
Moonlight is personal news intelligence for the Nigerian information ecosystem and global tech. It reads news sites, YouTube channels, and hard-to-reach pages on your behalf; classifies and embeds everything; filters it through your natural-language preferences; publishes a curated brief at 19:00 WAT every day; and answers questions about any story through a chat agent that cites its sources.
The goal: stop drowning in feeds. Let an agent do the reading, then hand you the eight stories that actually matter — and let you interrogate any of them in plain language.
Live AppTech Stack: FastAPI · Python · Postgres 17 · pgvector · SQLAlchemy 2.0 · Alembic · Gemini · Crawl4AI · Nuxt 4 · Nuxt UI v4 · TanStack vue-query · Coolify
Why This Exists
The Nigerian information ecosystem is fast, noisy, and spread across a dozen outlets, YouTube channels, and pages that don't even publish clean RSS. Staying informed means manually checking Guardian, Vanguard, Premium Times, Punch, Channels, plus a handful of tech feeds — every single day. Most of it is noise, the same wire story rewritten eight times.
Moonlight inverts that. Instead of you reading the feeds, an agent reads them, dedupes the repeats, clusters the rewrites into single stories, ranks them against what you said you care about, and hands you a brief once a day. Everything it surfaces is traceable back to the source.
How It Works
The whole system is a pipeline: pull raw items in, enrich them in stages, then serve the result two ways — a daily brief and a chat agent.
RSS feeds ─┐
YouTube ───┼─→ ingestion (30 min) ─→ raw_items ─→ pipeline (hourly)
Crawl4AI ──┘ dedupe: sha256(url) ├─ embed (pgvector, Gemini)
├─ classify (topics/entities/
│ substance, LLM)
├─ chunk (RAG retrieval)
└─ cluster → stories
│
┌────────────────────────┬──────────────────────────┬──────┘
preference engine 7pm digest RAG chat agent
(3-gate filter: (ranked stories, (tool loop: search,
source→rules→semantic) cached, idempotent) timeline, comments,
│ │ transcripts; cites
└────────────┬───────────┘ [item:N])
▼
FastAPI ─→ Nuxt web app
What's Built
| Feature | Description |
|---|---|
| Multi-source ingestion | RSS, YouTube (uploads + comments), and Crawl4AI for sites without clean feeds — polled every 30 minutes, deduped by sha256(url) |
| Embedding + classification | Every item is embedded with Gemini into pgvector, then classified for topics, entities, and substance by an LLM |
| Story clustering | Near-duplicate coverage of the same event is clustered into a single story, so you read it once, not eight times |
| Preference engine | A 3-gate filter — source → rules → semantic — ranks items against your natural-language preferences |
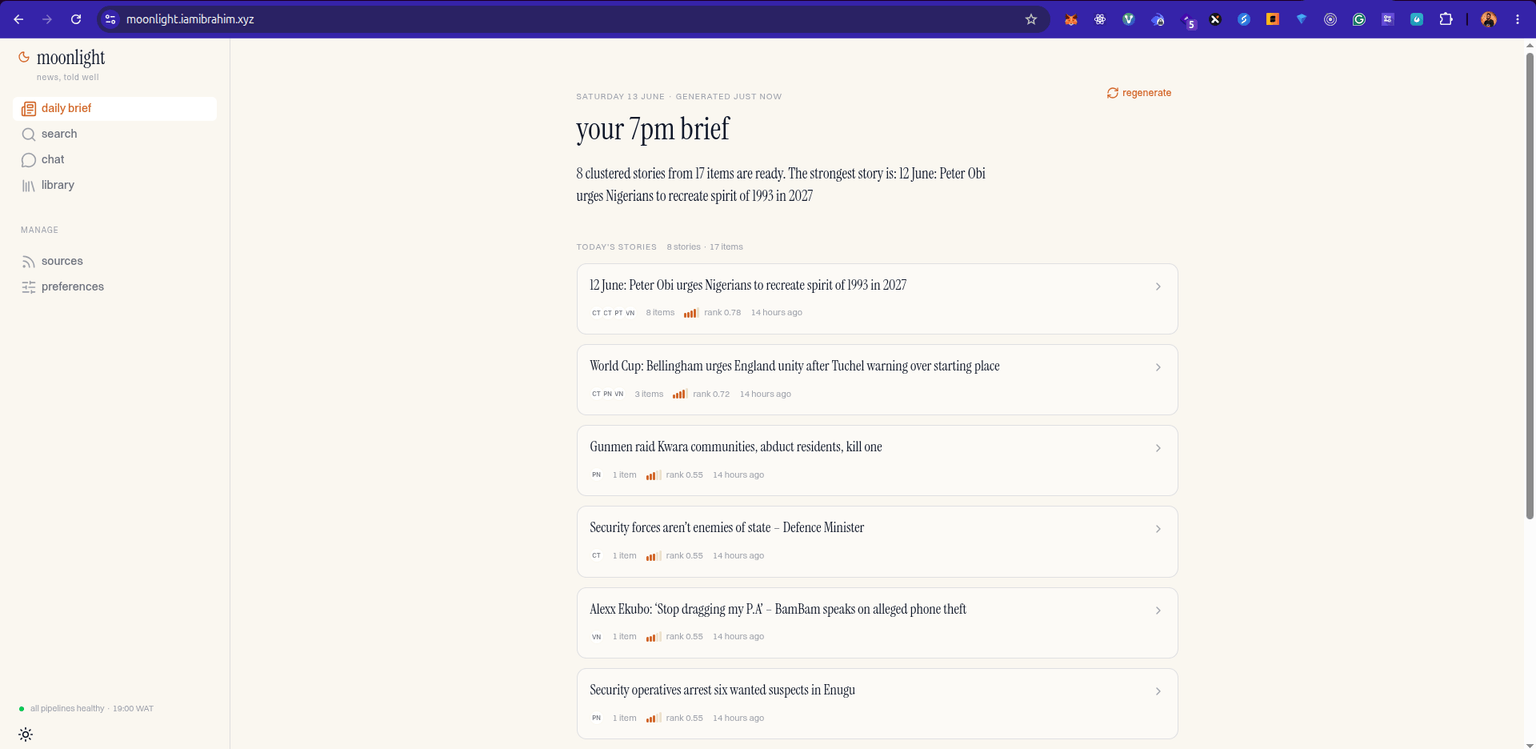
| 7pm daily brief | A ranked, cached, idempotent digest of the day's strongest stories, published at 19:00 WAT |
| RAG chat agent | Ask about any story; a tool-loop agent searches, builds timelines, reads comments and transcripts, and cites [item:N] for every claim |
Tech Stack
| Layer | Choice |
|---|---|
| API | FastAPI (async), SSE streaming chat |
| DB | Postgres 17 + pgvector, SQLAlchemy 2.0 async, Alembic migrations |
| Pipeline LLMs | Gemini — embeddings gemini-embedding-001, classify flash-lite, chat flash |
| Scraping | Crawl4AI + headless Chromium (robots.txt-respecting) |
| Web | Nuxt 4, Nuxt UI v4, Tailwind 4, TanStack vue-query, bun |
| Deploy | Coolify on AWS EC2 — one multi-stage image, three roles (api / ingestion / digest) |
Architecture
Moonlight is one codebase that deploys as a single Docker image with three runtime roles. The Postgres ORM models are the source of truth; the ingestion and pipeline workers are stateless and idempotent, so a missed run just catches up on the next tick.
server/ FastAPI app: routes, ORM models (source of truth), agent, migrations
ingestion/ source pollers: RSS, YouTube (uploads + comments), Crawl4AI
pipeline/ embed · classify · chunk · cluster · digest workers
web/ Nuxt app (per-page component folders, vue-query data layer)
deploy/ Dockerfiles + production runbook
tests/ pytest — pure-logic units for contracts, gates, chunking
Why pgvector instead of a dedicated vector DB?
The corpus is personal-scale — thousands of items, not billions. Postgres with pgvector keeps embeddings, relational metadata, and the classification graph in one database, one transaction boundary, one backup. A story's chunks, its source items, and its vector all live together, so RAG retrieval is a single SQL join, not a cross-service fan-out. No second datastore to operate.
Why a 3-gate preference filter?
Ranking purely by semantic similarity drowns you in plausible-but-irrelevant matches. Moonlight gates in order of cost: a cheap source allowlist first, then deterministic rules, and only then the expensive semantic comparison against your stated preferences. Most noise is rejected before it ever touches an embedding comparison.
Why one image, three roles?
The API, the ingestion pollers, and the digest generator share the same models and config. Building three separate services would mean three deploys and drifting dependencies. Instead, a multi-stage Dockerfile produces one image; the role is chosen at container start (api, ingestion, digest). One thing to build, one thing to version.
The Chat Agent
The brief tells you what happened. The chat agent lets you dig in. It's a tool-loop agent over the same pgvector store — it can search the corpus, assemble a timeline of how a story developed, pull YouTube comments and transcripts, and synthesise an answer. Every claim it makes carries an inline [item:N] citation that links straight back to the source item, so nothing it says is unverifiable.
Status
| Layer | Status |
|---|---|
| Ingestion (RSS · YouTube · Crawl4AI) | ✅ Shipped |
| Embedding + classification pipeline | ✅ Shipped |
| Story clustering | ✅ Shipped |
| 3-gate preference engine | ✅ Shipped |
| 7pm daily brief | ✅ Shipped |
| RAG chat agent with citations | ✅ Shipped |
| Production (Coolify on EC2) | ✅ Live |
Live at moonlight.iamibrahim.xyz — reading the news at 19:00 WAT, daily.